What Sets SkySQL Serverless Apart
November 6, 2024

We recently launched the first serverless cloud database for MariaDB — a truly free option for developers, with pay-as-you-go pricing. This marks a significant shift in simplifying scalability for modern applications.
Technical highlights
* Within a second, your database is launched —fully isolated and secure.
* Granular resource allocation ensures smooth scaling without disruptions.
* “Hot” micro DB servers restore seamlessly, for super efficient scaling from “zero”.
* Always-on connections, even when DB servers are scaled to “zero”.
* Maintaining consistent performance during scaling by automatically reloading the cache.
Why Serverless?
Unpredictable demand spikes are the new norm for databases.
The rise of AI tools like Copilot, Cursor.sh, and No-code frameworks has accelerated the pace of application development. We are nearing an era where AI could autonomously generate entire applications. As application numbers grow, so does the demand for Online Transaction Processing (OLTP) databases. Many of these AI-driven applications will create unpredictable and dynamic database interactions.
Global SaaS companies are also turning to serverless applications to manage rapid user growth. Capacity planning for every region is impractical, and platforms like Vercel, Firebase, and Netlify advocate for serverless functions that scale dynamically with demand. These functions rely on cloud databases with ephemeral connections, freeing developers from scalability concerns and tying costs to actual CPU usage.
But the key question remains:
Can the database scale as efficiently as the application while keeping costs under control? The common solution is to over-provision DB servers resulting in significant spend and waste. And, unanticipated large spikes still cause outages.
Auto-Scaling Everything?
The need is simple: scale up or out only when necessary, and scale back down when demand drops. Several prominent cloud databases already claim to auto-scale, allowing for vertical scaling to handle complex queries and horizontal scaling to support more concurrent clients. This works well for stateless applications, but it’s a different challenge for databases—especially OLTP databases with strict latency SLAs.
Several serverless databases claiming auto-scaling are already available in the market. However, most aren’t up to the mark. Auto-scaling for databases requires a more sophisticated approach due to the complexities of maintaining performance and availability during unpredictable demand surges.
Challenges with existing solutions
Compute-Storage Disaggregation
AWS RDS Aurora pioneered the idea of separating the database storage engine from its compute layer (responsible for parsing, planning, optimizing, and executing SQL). While appealing for various reasons, this design often leads to heavy traffic between the compute and storage layers, resulting in unexpected charges— surprise IOPS charges. On top of that, AWS Aurora Serverless doesn’t scale to “zero”. Several other databases have followed this model, including Google’s AlloyDB and Alibaba’s PolarDB.
This approach introduces complexity, making these forks of open-source databases harder to maintain. As a result, there is a high likelihood of behavior diverging from the original open-source versions. We’ve seen evidence of this with distributed databases like TiDB and PlanetScale.
Fully Distributed Databases
These systems typically scale by horizontally partitioning data across multiple nodes. Scaling requires repartitioning data between the old and new nodes, which can be expensive and prone to locking. This method complicates scaling, especially during operations that demand high availability.
The SkySQL Approach: Cloud-Native, No Forking Required
We believe the InnoDB storage engine is the most advanced and mature OLTP storage engine available. There’s no need to re-architect this proven layer. Instead, we focus on scaling using truly cloud-native techniques—scaling vertically by adding compute power and horizontally by adding nodes to the cluster—both quickly and without disruption.
SkySQL extends Kubernetes with custom-built controllers that allow for fine-grained resource control. This approach enables us to:
Provision resources in small chunks to scale efficiently.
Offload and hydrate database caches from fast SSD drives to optimize performance.
Pool “hot” DB containers to enable fast cold starts or restarts.
Bring up replicas rapidly using incremental snapshots at the storage layer.
Our cloud-native method enhances scalability without sacrificing the stability and reliability of the mature open-source InnoDB engine.Here is a high level view into the Architecture. Discussed below.
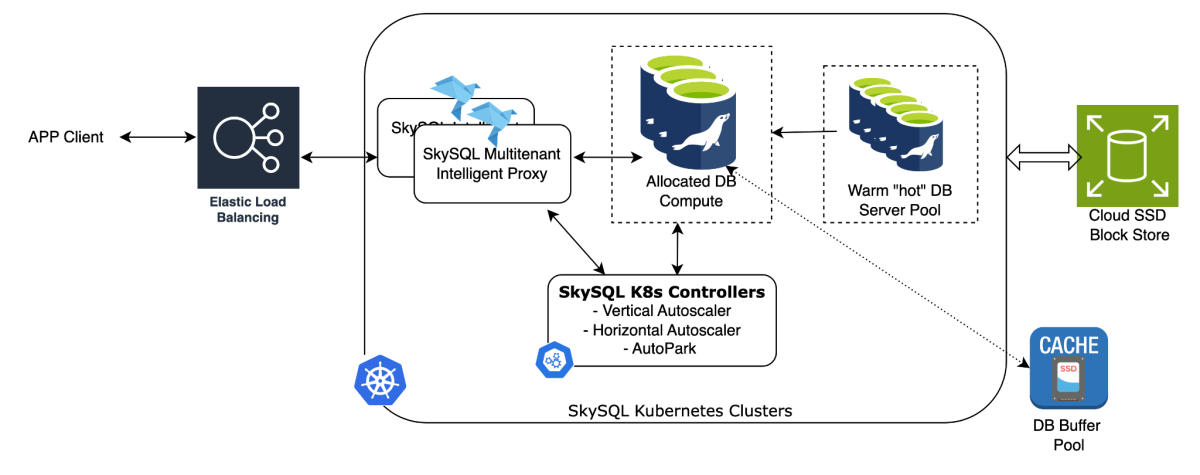
Diving Deeper: Key Techniques Powering SkySQL Serverless
Effortless, Fast Cold Start We maintain a pool of “hot” pre-built DB servers across multiple clouds and regions. When you launch a new database, it’s simply a matter of checking out a pre-configured server, creating the necessary users, binding the storage volume, and securing the endpoint. In an instant, your database is ready—fully isolated and secure. There are no shortcuts like multi-tenant setups; every database operates independently.
Super Fast Vertical Auto-Scaling By extending Kubernetes with custom controllers, we can precisely manage resource allocations for DB containers. We closely monitor database load—based on concurrent client activity and the moving average of CPU usage—to determine when to scale up or down. Scaling happens in small increments, as little as 0.5 vCPU and proportional memory, without disrupting connections, locking the database, or adding overhead.
Delivering Consistent Performance During Auto-Scaling A critical factor for low-latency performance is the database cache (buffer pool). When the database auto-scales, we proportionally expand the buffer pool and automatically reload the most relevant data blocks into memory, maintaining the same high cache hit ratios you’d expect from a provisioned environment. This avoids the need to access expensive shared storage layers, keeping IOPS charges out of the equation.
“Hot” Micro DB Servers for Fast Scale-Ups Even during idle periods, we don’t eliminate the DB server process. Instead, we shrink it down while keeping the database in its initialized state, offloading the cache to high-speed SSDs. When workloads resume, we simply adjust resource allocations and restore the cache, allowing operations to scale seamlessly. Performance is generally identical to when the database was fully “hot.” We only remove the DB server entirely if it’s idle for a full day, such as with development databases—and you’re never charged for these micro DB servers.
Always-On Connections For serverless databases to match the high availability (HA) of provisioned servers, connections must remain active regardless of the server process’s availability. To achieve this, we employ a multi-tenant, scalable intelligent proxy that keeps connections alive. When activity resumes, the proxy collaborates with our Kubernetes extensions to resurrect the database server. Our proxy also load balances requests, maintains HA, and caches session states (e.g., transaction isolation levels), replaying them when the server is restarted.
There’s much more we haven’t covered, such as horizontal scaling and live server migrations, but the techniques above highlight how our serverless platform is designed to deliver truly instant auto-scaling. Expect a lot more insights in the near future with more in-depth technical blogs, where we’ll dive deeper into the technology that makes SkySQL Serverless a game-changer.
In conclusion, SkySQL offers a powerful, always-on database that you can deploy today for free. Just visit app.skysql.com to get started. While serverless OLTP databases that can instantly scale connections, compute, and storage without disruption are hard to perfect, we’re on the path to achieving this. Stay tuned for even more sophisticated features in the coming months. We’d love to hear your thoughts and feedback as we continue to improve—reach out at support.skysql.com or via email at [email protected].