SkySQL Serverless Deep Dive: Blazing Fast Starts, Intelligent Scaling
May 16, 2025
At SkySQL, we fundamentally believe that the future of cloud databases will be built around a serverless model—one that doesn’t rely on fixed provisioning. These databases will be designed to handle a wide variety of workloads: from transactional and analytical to semantic search, each powered by purpose-built engines optimized for specific tasks.
With the rise of Generative AI applications, where agents dynamically decide which SQL queries to run, the demands on cloud databases will become increasingly unpredictable, and it will become increasingly difficult to predict the true capacity required in advance. Instead, cloud databases will rely on AI-powered intelligence to continuously assess and adjust resource needs on the fly.
And the best part: users will only pay for the resources they actually consume, making the whole process more efficient and cost-effective.
This blog builds on our high-level introduction to SkySQL serverless architecture [previous blog link]. We suggest reading that first if you haven’t already.
In this deep dive, we’ll take a closer look at some of the most crucial aspects of a serverless database, including cold start latency, auto-scaling, and high availability, and share our approach to making these features work seamlessly for you.
Compute-Storage Isolation: Achieving Efficiency Without Changing the DB Storage Engine
The goal of serverless architecture is simple: allocate resources only when needed and deallocate them when idle. While this is straightforward for stateless applications, databases present a unique challenge. You’re not just dealing with processing power—you have to manage session state, caches, buffers, and data storage.
A logical solution to this problem is to separate the data storage from the compute layer. This concept has been popularized by services like AWS Aurora, which redefined the storage layer by significantly modifying the database kernel. However, this approach introduces complexity, often with questionable benefits. From our perspective, it’s important to stay true to our core mission: to maintain a truly open-source solution.
We asked ourselves some fundamental questions:
Is it necessary to offload transaction processing (like redo logs or Write-Ahead Logs) and DB page handling for the wide variety of workloads we support daily?
Can we realistically implement a rock-solid, multi-tenant storage layer across different regions, zones, and cloud providers?
Is it acceptable to introduce opaque storage costs, like unpredictable IOPS charges?
Let’s dive into these considerations:
Maturity Challenges: Redefining the storage layer, as seen with Aurora and Neon, often means overhauling the entire storage engine, which introduces potential bugs. The maturity of solutions like InnoDB mitigates this risk, providing a more stable foundation.
Compatibility Hurdles: Despite years of development, Aurora and similar solutions still face challenges with full compatibility with traditional databases like MySQL or Postgres, especially when migrating mission-critical applications to new platforms. This makes seamless integration with legacy systems difficult.
Cost Considerations: Shared storage is efficient for large providers but can become costly for smaller players, especially when accommodating burst demands. Hidden costs like IOPS charges in Aurora highlight the unpredictability of pricing.
Query Performance: While serverless architectures aim for scalability, OLTP workloads often end up consuming more CPU and IO, affecting performance. In some cases, benchmarks have shown that a single MariaDB instance can outperform Aurora, questioning the separation of the storage layer.
Our Approach: Keeping It Simple and Open
At SkySQL, we adhere to a core principle: don’t change what works. We leave the mature, open-source engine intact, which allows us to focus on other areas of innovation. By leveraging native Kubernetes capabilities, we can achieve sufficient isolation of database storage volumes without the need to fundamentally alter the database engine itself. An approach that allows multiple DB engines to be easily supported.
Using Kubernetes, we can dynamically attach volumes to containers, seamlessly scale block storage as required, and maintain the high levels of flexibility and efficiency required for serverless architectures. This approach gives us the best of both worlds: leveraging the power of a mature, open-source database engine while achieving the flexibility and scalability needed in a serverless model.
Launch in Milliseconds: Simpler Than You Think
Whether it’s developers using modern “prompt-to-app” platforms like Replit, Lovable, or DevOps pipelines running automated tests—launch, load, teardown—it’s become essential to launch a new database in milliseconds.
While cloud providers and Kubernetes offer auto-scaling features, such as expanding NodePools or dynamically scaling pod counts, these solutions didn’t meet our needs. Node creation often takes over a minute, with large variances. Additionally, stateful Kubernetes pods are slow due to the time required for disk volume attachment.
In database creation, initialization typically involves storage allocation and data file creation, like .ibd files for InnoDB tables or .frm files for table structures. For larger databases, buffer pool memory allocation also takes time. While these steps are relatively inexpensive in aggregate, they still exceeded our time budget for near-instant database launches.
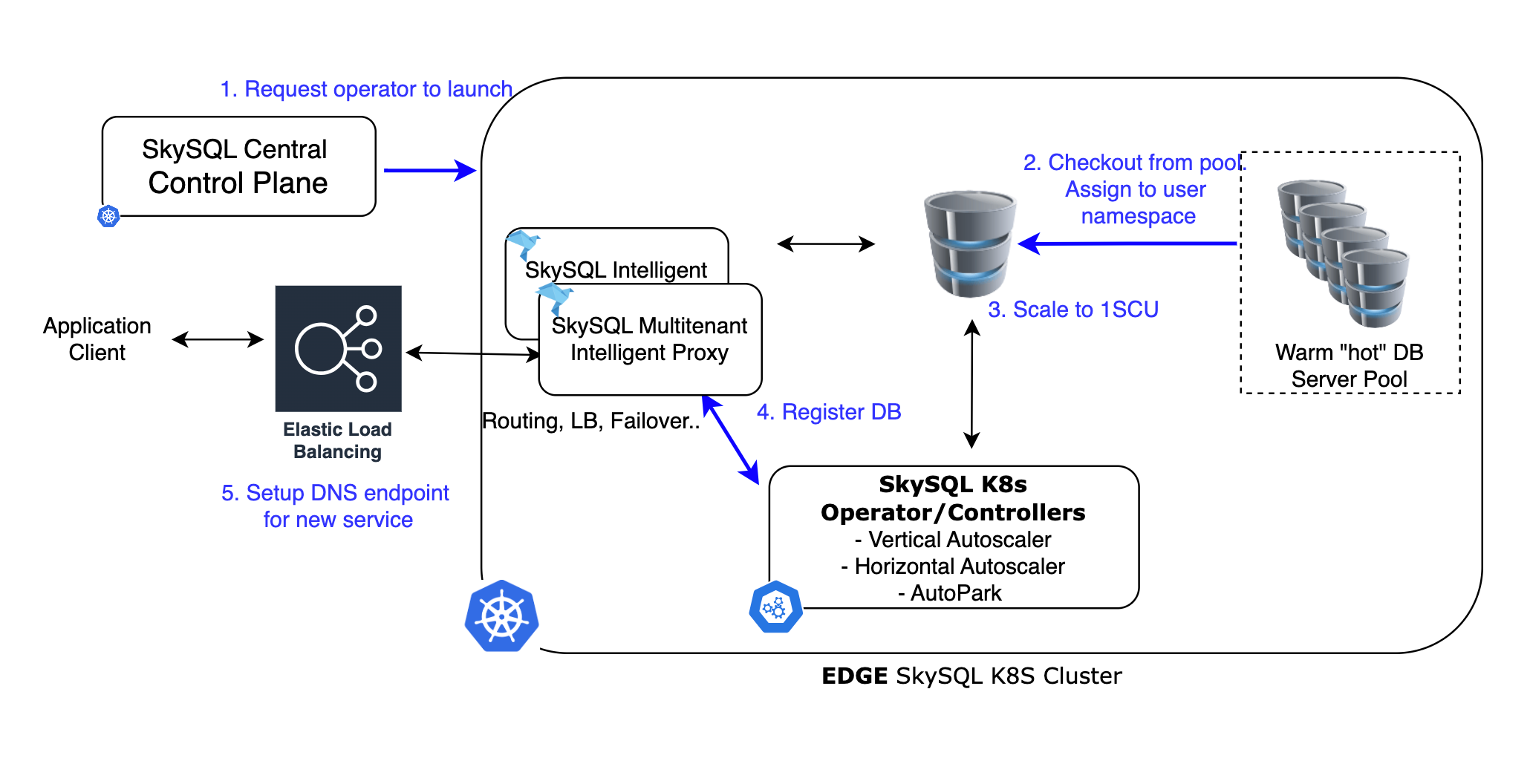
In SkySQL, we use adaptive pools of pre-fabricated “micro” databases. These databases are set up with sensible default configurations, attached to a starter storage volume, and ready to go. We maintain these pools in all global regions where we support serverless databases.
Each database server instance is essentially a Kubernetes pod requesting minimal compute resources. We don’t need to worry about sizing the buffer pool or caches—everything is resized dynamically via our auto-scaling engine.
When a user requests a new database, it simply checks out a database from the pool, resizes it according to the configuration (e.g., a default free serverless DB gets 0.5 vCPU and 2GB memory), runs security procedures like setting up the DB user, configuring a secure endpoint and tracking in our control plane. Then, the database is ready. The “warm DB” pool is continually replenished in each region based on demand.
The graphic below shows the process at a high level.
Achieving Rapid Vertical Auto-Scaling
SkySQL leverages large cloud compute instances, typically with 16 vCPUs and 64GB of memory, to manage database pods. These nodes are then carved up and allocated to multiple individual database pods based on their resource requirements. Auto-scaling happens in 0.5 vCPU and 2GB memory increments.
Most of our auto-scaling functionality is built using Kubernetes extensions (custom controllers).
One potential solution was In-place Resource Resize for Kubernetes Pods, introduced in K8s v1.31. However, we opted out of using it for a few reasons:
The feature was still in Alpha in Kubernetes v1.31.
We required granular control, zero disruption to ongoing database operations, and fast response times—something the feature couldn't guarantee.
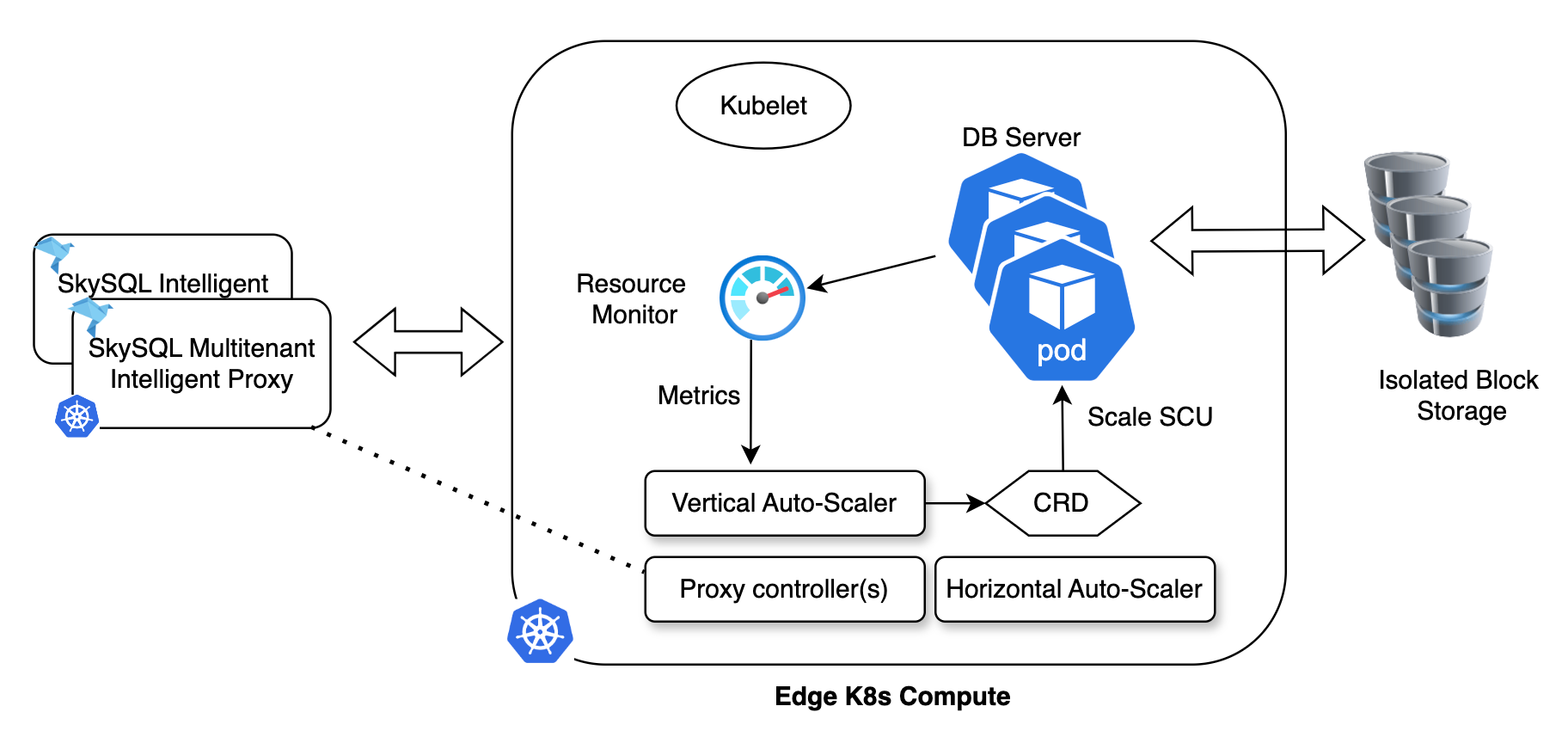
Instead, we use custom Kubernetes controllers to dynamically allocate resources to database pods. Here’s how it works:
A Resource Monitor controller tracks CPU and memory usage and reports the data to a central coordinator. The coordinator sets upper and lower scaling limits (e.g., a free-tier server cannot scale beyond 2SCUs).
A Scaling Controller acts on these decisions and uses the Container Runtime Interface (CRI) API to adjust resources.
We rely on Linux Control Groups (cgroupsv2) under the hood to manage resource allocation.
Scaling Algorithm:
Every running Serverless instance runs a daemon and accumulates the UsageCoreNanoSeconds from the container stats once every 200 milliseconds for a 30-second sliding window. We effectively compute the moving load average aggressively to potentially trigger a scaling event. The computation is designed so we don’t react to isolated, expensive operations.
Here is a mental model:
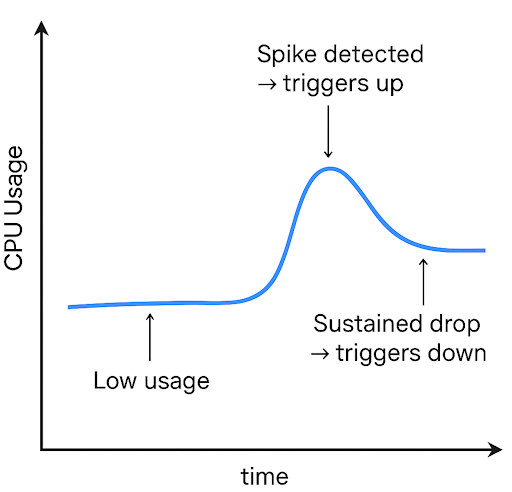
Analogy: Think in terms of "CPU burn rate" over a window
You're watching how fast the CPU "spends" its time budget.
If it’s burning close to its limit (like 900ms out of 1000ms in 1s), it's nearly saturated → scale up.
If over 30s the average burn is low (e.g., only 20% used), it's underutilized → scale down.
What's actually happening:
Every 200ms, SkySQL samples CPU usage (how much total CPU time was consumed).
For every decision:
Scale-up: looks at just the last 1 second. If the system is within 100ms of the current SCU's CPU time budget, it triggers scale-up.
Scale-down: uses a 30s window, which smooths short-term dips to avoid unnecessary downscaling.
No active connections for 10s: immediately scales to 0 SCU, regardless of usage.
DB properties are also tuned:
When scaling up, we adjust key DB properties:
Increase the maximum number of connections or threads the DB can handle.
Proportionally increase the buffer pool size to match the new resource allocation.
While scaling up happens in near real-time, we introduce a cooldown period—around 30 seconds—before scaling down. During this phase, we reverse the scaling-up steps:
Decrease the max connections/threads available.
Proportionally reduce the buffer pool size to reflect the decrease in resources.
Automatic Buffer Pool Hydration for Consistent Performance
The DB buffer pool, a cache of database disk blocks, is the single most important component impacting database performance. Every time the database scales up or down, the buffer pool size is adjusted. We use a specialized Kubernetes controller to manage the buffer pool dynamically.
When the database scales up, the buffer pool starts filling with data. If the DB later scales down, a simple approach would be to simply reduce the size. However, if the DB scales up again, the previously increased buffer pool may remain empty, leading to more cache misses and a performance hit.
To prevent this, we track the most frequently used pages in the buffer pool on high-speed SSD storage before reducing its size. Instead of dumping every single page, we only track the page IDs of the most commonly accessed data. This operation is extremely fast. When the database scales up again, we automatically rehydrate the buffer pool by loading these frequently used pages back into memory. A background process fetches the corresponding blocks from disk, ensuring that the cache is quickly refilled.
This automatic faulting of commonly used data into memory ensures that query performance remains consistent, even during scaling operations.
Suspending and Parking DBs
When application activity drops to zero, we first scale down the resources allocated to the database server. This involves removing active threads, freeing up memory used by DB sessions, and reducing the buffer pool to the minimum required by InnoDB to keep the database running. At this point, the DB is considered to be in a “Suspended” state.
While the database server is suspended, we never terminate application connections—for instance, when an app uses a persistent connection pool. These connections remain active and are routed through an Intelligent Proxy, described later in the blog.
If any application connections become active again, the DB server thread pool expands to meet the demand, the buffer pool is rehydrated in the background, and the database becomes fully operational instantly.
After several hours of inactivity, the DB server and pod are terminated, and the DB is considered “parked.” Upon resumption of activity, the pod is automatically recreated and reattached to its storage volume. We are actively optimizing this resumption time.
Auto-scaling Storage
We continuously monitor the usage of each PersistentVolumeClaim (i.e., for each DB) and trigger scaling up when certain thresholds are breached. These thresholds vary with the current size of the allocated storage. For instance, we may start the scaling operation at 60% capacity for a 20GB volume, whereas we start scaling at 95% for a 500GB volume. Effectively this ensures that the scaling operation completes before the application runs out of storage. Today, we leverage the block storage technology (e.g., EBS in AWS) but are evaluating self-managed distributed storage solutions like Ceph/Rook.
Transparent Live-Migrations for Horizontal Scaling
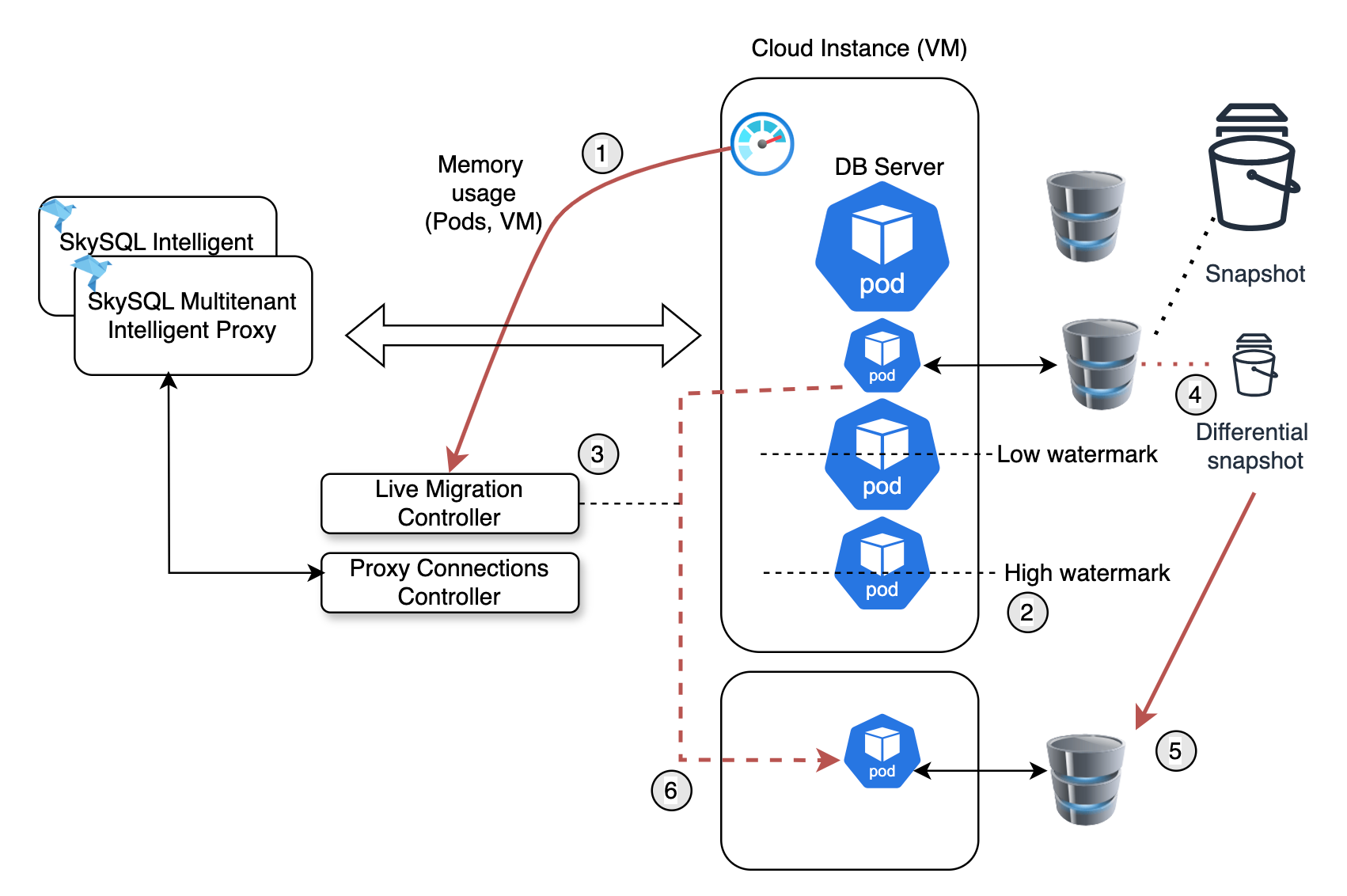
Horizontal scaling in SkySQL is made possible through transparent live migrations.
As database activity increases, DB pods can quickly exhaust the available resources (CPU, memory) on the provisioned instance. However, we need to ensure that the database can scale indefinitely, based on user-defined limits. To achieve this, we need to efficiently and transparently migrate workloads to other instances—essentially, "live migrate" the databases to other cloud instances. With zero interruptions or pauses.
The migration process begins when instance utilization hits a “high watermark” (around 70% memory). Our first step is to identify the least-used DB pods—those that are dormant or infrequently accessed. We then look for target nodes that have sufficient resources (at or below a “low watermark”). If no suitable target instances are found, new instances are automatically provisioned via the Kubernetes NodePools.
To perform the migration, we:
Recreate the DB pod on the target instance using a snapshot.
Set up a replication channel to the current active “primary” DB pod.
Once the replica is fully synchronized, we use our intelligent proxy to transparently redirect the connections to the new database endpoint.
While the initial snapshot may take time (and could be resource-intensive), all subsequent snapshots are differential, making them much faster. Moreover, most snapshots are often generated during an automated backup process that runs periodically.
The entire live-migration process is proactively initiated and happens transparently, with no disruptions to the application’s ongoing operations.
Always-On Connections and the Intelligent Proxy
All traffic to the database servers passes through a multi-tenant proxy. The proxy acts as a buffer, handling connection requests and directing traffic to the appropriate database instance.
For serverless databases to provide high availability (HA) like provisioned servers, connections must remain active, even when the database server is in a standby or parked state. To achieve this, we use a scalable, intelligent proxy that keeps connections alive, regardless of the database’s state.
A dedicated Kubernetes controller ensures that the proxy is aware of scaling decisions in real time. For example, when there is no activity in the database connections, the proxy may decide to terminate all database connections while keeping application connections active. When activity resumes, the proxy automatically re-establishes the database connections. If the database is restored from a parked state, the proxy works with Kubernetes to identify the new pod endpoint and directs the connection accordingly.
When a database is live-migrated, restored from a cold state, or has terminated database connections, session state needs to be re-established. For instance, the application may set system variables like:
1SET @@session.sort_buffer_size = X;Or user variables like:
1SET @myvar = 'value';The application may also use prepared statements that need to be re-established. The proxy tracks all session state and simply re-creates it on the new connection, ensuring the application continues smoothly.
Inherently Highly Available
Since the proxy holds application connections and can recreate session state, it also inherently supports database failures. If a database instance crashes or is unavailable, the proxy will wait for Kubernetes to recreate the pod elsewhere and will resume the database connections automatically.
The proxy also tracks ongoing transactions and will replay any partial transactions, ensuring that there is no data loss during failover. This ensures high availability and data integrity, keeping the application unaffected by database failures.
Start Building Today—For Free
Ready to try it yourself? Get started with SkySQL’s free serverless developer tier, you can deploy your cloud database instantly. No credit card. No provisioning. Just launch, connect your app, and query.
For feedback, comments, or questions, please join our SkySQL Discord channel.