Optimizing Database Resilience and Cost: A Deep Dive into SkySQL’s Unique Features
March 12, 2024

Open-source databases like MariaDB, MySQL, and Postgres are established powerhouses. They boast rich features and their SQL dialects are fluent to developers, backed by a robust ecosystem of tools. However, the cloud changes the game. Operational characteristics now reign supreme: seamless scaling, rock solid security, effortless migration and replication, guaranteed uptime, and most importantly, delivering on the cloud’s cost-saving potential.
It is a common misconception that cloud database management and optimization is a solved problem. In reality, databases are still notoriously difficult to operate efficiently and cost effectively. Many of our customers and prospects have shared experiences of prolonged outages, challenges in achieving consistent performance at scale, and unsustainable costs associated with alternative cloud database services.
In this blog, we’ll delve into how SkySQL tackles these challenges.
1. Unmasking HA Gaps: A Closer Look at Database Resilience
While virtually every cloud database solution touts high availability, this often does not translate into continuous availability. The transition from an active server to a standby can often take minutes or longer, resulting in prolonged disruptions which can be catastrophic for mission critical applications.
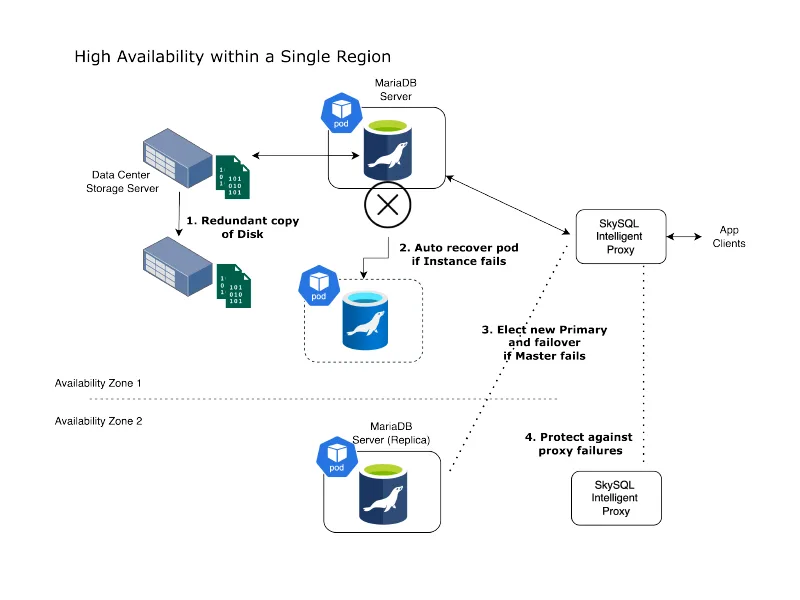
To provide high resiliency we try to protect every layer of the stack – disks, compute, Zones/cloud regions, network and even the load balancer accepting incoming DB connections. The graphic below depicts this architecture. Letʼs peel the onion a bit.
All Cloud databases configured for HA replicate the data across multiple availability zones (AZ). Ensuring your data is protected against data center failures. This is necessary, but not sufficient. In SkySQL, data is always isolated from compute on the underlying block storage device of each AZ. This device keeps a copy of each block on multiple servers providing the first layer of protection against component failures or corruption.
The deployment of DB servers occurs within containers orchestrated by Kubernetes (k8s). In the event of cloud instance failures, SkySQL’s health monitoring prompts k8s to revive the container in an alternate instance, seamlessly reconnecting to the same storage volume. AWS RDS, for example, runs MariaDB on VMs requiring a replicated setup for any protection against node failures.
While hardware failures are a possibility, a more common scenario we see in practice involves a DB crash due to resource exhaustion or timeouts—such as running out of allocated temp space due to rogue queries or an unplanned large spike in data load. In such instances, it is crucial for application connections to smoothly transition to an alternate server.
Behind the scenes, SkySQL consistently directs SQL through its intelligent proxy. This proxy not only continuously monitors servers for failures but also remains acutely aware of any replication lags in the replica servers. Should a primary server fail, an immediate election process ensues to select a replica with the least lag. Simultaneously, attempts are made to flush any pending events, ensuring synchronization and full data consistency. Any pending transactions on the primary server are also replayed. Collectively, these measures enable applications to operate without connection-level interruptions or SQL exceptions. Achieving heightened levels of High Availability (HA) is effortlessly attainable by expanding the number of replicas. Replication can even extend across different cloud providers or to a self-managed (ˮpeace of mindˮ) replica within a customerʼs own environment.
In contrast, the high availability behavior in Google’s CloudSQL (MySQL) or AWS RDS (MariaDB) relies on a standby replica. When the active server encounters a failure, the standby is elevated to the position of the new active server. This transition, however, is a time-consuming process, exceeding 2 minutes based on our experiences, and varying according to the nature of the failure. In SkySQL, failover on a server crash happens within a few seconds.
AWS RDS utilizes a DNS-based approach for failover, where the DNS record is updated to direct to the new primary instance. Moreover, application clients tend to cache DNS records and may not diligently adhere to the DNS TTL (time-to-live) configuration.
The ultimate consequence often manifests as connection failures on the application client side, potentially leading to an outage.
2. Scaling Concurrent Users without Compromising Consistency
Cloud offerings of open source relational databases often achieve scalability by distributing data across a cluster of nodes, often relying on a replication model where ‘writes’ to the primary node are asynchronously transmitted to one or more replicas. Typically, the onus is on the customer to manage the distribution of traffic across the cluster, either through client application logic or by configuring a proxy service. Several customers have told us that this is simply too big a challenge, effectively capping the scalability of these cloud solutions. Even when customers successfully navigate this challenge, with this approach data consistency might not be uniform across the entire cluster at any given moment.
When application client connections are evenly load balanced across these replicas for ‘reads,’ the application must either tolerate potentially stale reads or consistently direct all requests to the primary, severely limiting scalability. Replicas are relegated to offline tasks like reporting — a common scenario from our observations in AWS RDS.
Contrastingly, in SkySQL, the intelligent proxy maintains consistency without compromising its ability to load balance requests across replicas, supporting both ‘causal’ and ‘strong, global’ consistency models. Essentially scale for concurrency without losing consistency. Let’s delve deeper.
Causal consistency ensures that ‘reads’ are fresh only concerning the writes they are causally dependent on. For instance, when an app client executes a ‘write’ followed by a ‘read,’ it expects to see the changed value, causally dependent on the preceding ‘write.’ This sequence may need to be satisfied exclusively by the primary if the replicas lag behind. Concurrent clients, however, continue to be load balanced across all servers.
This model functions optimally when application clients utilize sticky SQL connections. However, in the modern landscape where applications are often distributed (micro services) and rely on connection pooling frameworks, a ‘write’ and the subsequent ‘read’ might occur on different connections. To ensure consistent reads, awareness of the ‘lag’ at a global level is imperative. Fortunately, this is seamlessly achieved with a simple switch in SkySQL. If the ‘write’ rate is moderate and the replicas can keep up (a prevalent scenario in practice), clients continue to uniformly utilize the entire cluster.
2.1 Doubling Throughput Compared to RDS MariaDB or GCP CloudSQL
SkySQL achieves superior throughput and reduced latencies compared to the standby replica approach in RDS or GCP CloudSQL by meticulously monitoring incoming SQL and the state of the replicas. Unlike RDS or GCP, where the standby is typically unused for client requests (wasting resources), SkySQL maximizes the available compute power across all nodes, delivering unparalleled cost effectiveness.A notable feature enhancing performance is the ‘Read-Write Splitting,’ allowing for custom routing to achieve consistently lower latencies for specific application patterns. For example, point queries and index-optimized queries can be directed to select nodes hosting frequently accessed data, while more resource-intensive scan-aggregation class queries (such as those for reporting dashboards or complex queries based on end-user selections of historical data) can be routed to a separate set of nodes. These routing strategies effectively segment actively used data sets, optimizing the DB buffer cache and resulting in lower latencies.The implementation of these routing strategies is straightforward, primarily through the use of “Hint Filters.” Standard SQL comments are utilized to customize routing to the appropriate server. Additional details on Hint Filters and Read-Write Splitting can be found in the MariaDB documentation.
3. Disaster Recovery – Across Regions, Cloud Providers, or “Self-managed” Environments
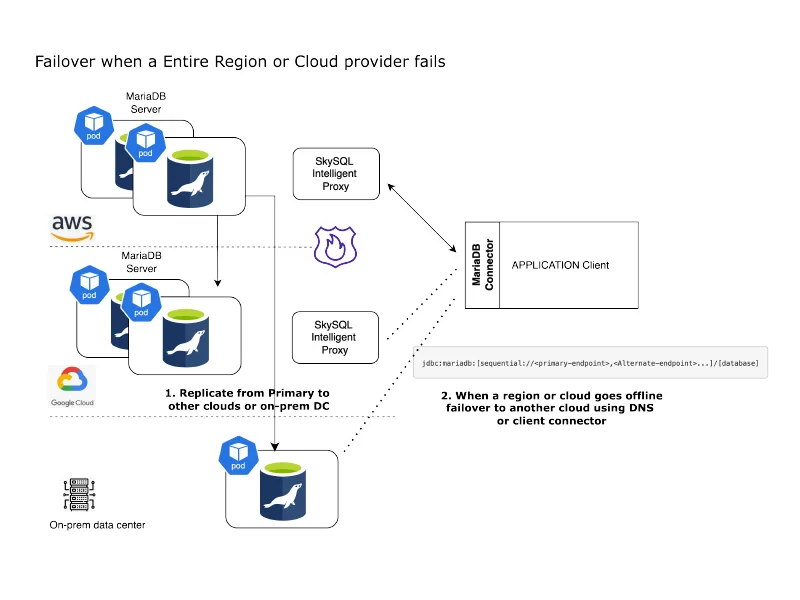
The major cloud providers tout disaster recover across regions, ensuring resilience against natural disasters impacting an entire geographical region. But in reality, such disasters are exceedingly rare. Whatʼs far more common are technical issues impacting an entire region for a specific cloud provider. For instance, we’ve encountered DNS-level failures in GCP regions, rendering all services dependent on DNS, including SkySQL, inaccessible.
One effective strategy to mitigate such risks is to replicate data to a data center owned by a different cloud provider within the same geographical area, minimizing network latencies. Disaster recovery across cloud providers is of course something an individual provider such as AWS or GCP simply donʼt support. Alternatively, customers can maintain their own “standby” database for emergencies—an environment entirely under their control, ensuring a near-real time copy of the data at all times.SkySQL empowers users to configure “external” replicas that can run anywhere, offering flexibility and resilience.
To facilitate this, SkySQL provides several built-in stored procedures for configuring both “outbound” and “inbound” replication to any compatible MariaDB or MySQL server environment. This flexibility allows users to tailor their disaster recovery strategy based on their specific needs, whether replicating across regions, cloud providers, or maintaining self-managed standby environments.
4. Auto-scaling for Optimal Resource Management
In the realm of database administration, the delicate dance between achieving peak performance and managing operational costs is an enduring challenge. Often, the default strategy involves planning and allocating resources based on peak usage, leading to over-provisioning.
Unlike AWS RDS MariaDB, which only offers storage autoscaling, SkySQL offers advanced auto-scaling capabilities for both compute and storage.
Predictive Scaling for Proactive Resource Allocation
SkySQL’s auto-scaling functionalities are guided by practical database management principles. It continually monitors the concurrent active sessions, establishing correlations with CPU utilization and observing the growth in disk usage. Rather than reacting impulsively to short-term spikes or outliers, SkySQL’s approach revolves around predicting sustained patterns.
For instance, if the system anticipates that a surge in concurrent activity is on the verge of pushing the current instance type to its limit in the next few hours, SkySQL takes proactive measures and automatically scales up. Conversely, when demand subsides, the system scales down, ensuring optimal resource utilization and cost efficiency.
By enabling customers to pay solely for their actual consumption, this feature alone, when considered independently of the additional automation benefits, can yield significant cost savings in comparison to operating a self-managed MariaDB or MySQL community server on the cloud. This holds especially true for development and test databases which can be scaled down or even paused outside of business hours.
The current functionality and policies are tersely described here.
Continuous Refinement for Enhanced Control
Recognizing the dynamic nature of database workloads, SkySQL’s auto-scaling is an evolving feature. Expect continuous refinements in the near future to provide administrators with greater control, improved predictability, and a reduction in administrative overhead.
5. Fractional DBA
With other cloud database providers, customers often find themselves with fairly minimal customer support, lacking proactive assistance in the management and optimization of their cloud databases.
SkySQL offers SkyDBA, a “Fractional” DBA Service unique in the industry, designed to be a cost-effective solution for organizations seeking expert database administration without the financial burden of employing a full-time administrator. This service provides access to a team of experienced database administrators that can analyze use cases and workloads, and provide proactive database management and performance optimization. This results in not only improved and consistent performance, but also preemptively addresses potential issues and minimizes the risk of outages before they occur, providing additional reassurance and peace of mind.
6. Achieving Data Consistency in a “Not Only SQLˮ Environment
In the era of Serverless apps and microservices, JSON has become the de facto standard for data interchange. It is common to witness the simultaneous use of JSON and SQL in the same application. A data stream of JSON documents is managed in a Document DB like MongoDB, catering to some use cases, while the same data is flattened and stored in an SQL DB like MariaDB, serving another subset of use cases, such as reporting. Often, both sets of data are presented together to the same users. The glaring challenge with multiple DBs hosting data is consistency, not to mention the complexity of data movement, transformations, and configuring disjointed DBs.
Why not store data as JSON but serve both MongoDB clients and SQL clients from the same consistent copy of data? SkySQL achieves this interoperability by exposing two ports—one that understands the MongoDB wire protocol and another for the MariaDB/MySQL wire protocol. Data resides in a single DB regardless of the source.
Internally, all documents are stored in a table containing two columns: an id column for the object id and a doc column for the document itself.
When the MongoDB® client application issues MongoDB protocol commands, the SkySQL proxy converts them into the equivalent SQL and executes them against the MariaDB backend. The MariaDB responses are then converted into the format expected by the MongoDB® client library and application.
For SQL clients, MariaDB provides a rich library of JSON functions. A SQL client can easily fetch a flattened view of nested JSON using the JSON_TABLE function.
Here is a simple SQL example to convert JSON to a flat relational structure. SQL views can further simplify use for SQL clients.
1set @json='
2[
3{"name":"Laptop", "color":"black", "price":"1000"},
4{"name":"Jeans", "color":"blue"}
5]';
6select * from json_table(@json, '$[*]'
7columns(
8name varchar(10) path '$.name',
9color varchar(10) path '$.color',
10price decimal(8,2) path '$.price' )
11) as jt;
12+--------+-------+---------+
13| name | color | price |
14+--------+-------+---------+
15| Laptop | black | 1000.00 |
16| Jeans | blue | NULL |
17+--------+-------+---------+To sum up, we’ve provided an overview of our key resilience capabilities, highlighting unique advantages while optimizing costs and complexity through auto-scaling and the utilization of fractional expert DBAs. At SkySQL, our commitment to excellence is unwavering. We consistently adapt our services, incorporating technological innovations and user feedback to maintain a leadership position in reliability, efficiency, and innovation within the market.
We encourage you to witness the difference firsthand. Try SkySQL. Tell us what you think.